Use Screaming Frog for Technical SEO
Screaming Frog is a powerful SEO tool that can be used to crawl websites and gather information about various elements.
Prerequisites
Visit the Screaming Frog website (https://www.screamingfrog.co.uk/seo-spider/) and download the latest version of the Screaming Frog SEO Spider. - Install the software on your computer.
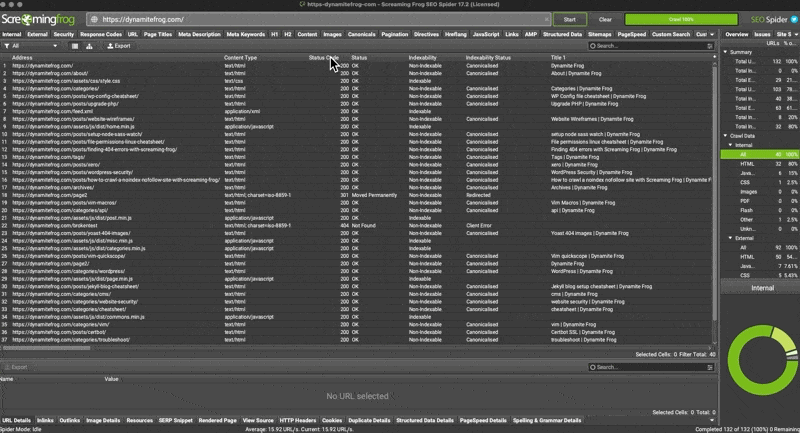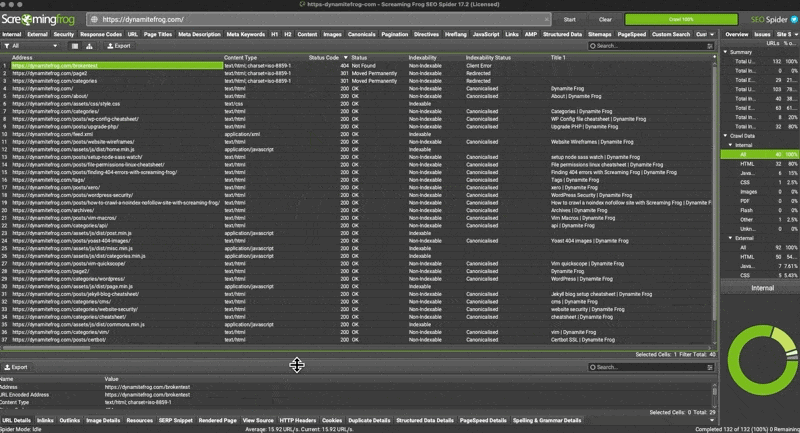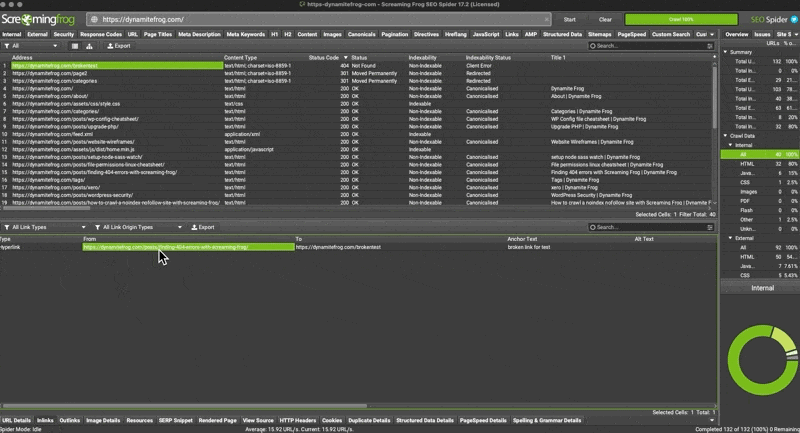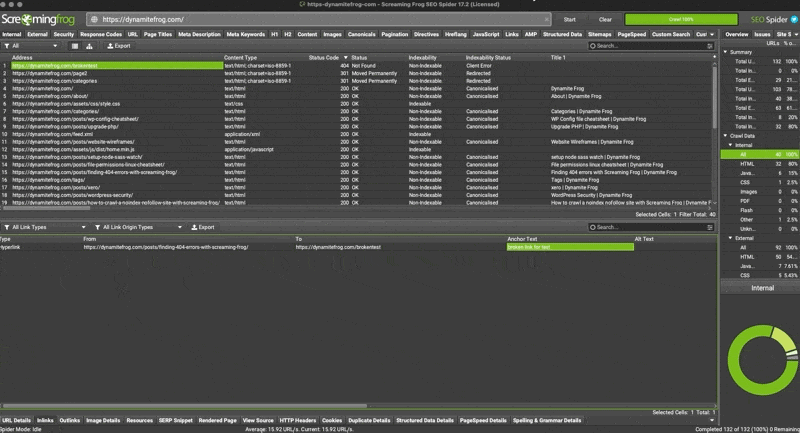
Finding 404 errors
- Run the crawl on the url
- Filter by status code until 404 descend from the top
- Select any of the 404’s from the returned results.
- Look at the footer menu of Screaming Frog for “inlinks”
- Right click the url from the “from” column
- Hit open from in browser
- Search for the anchor text of the broken link by doing a “command f” in your browser window
 find 404’s with Screaming Frog Crawl
find 404’s with Screaming Frog Crawl
If you can’t replicate the broken link in Screaming Frog
- If you cant replicate the link it could be that you are logged in and therefore cant replicate the error. Test the broken link in a non-logged in state.
- Try search the html source code if the search for the string on the website frontend returns 0 correct results
Exclude URLs from Screaming Frog crawl
Go to configuration > exclude
Exclude word from the crawl
This regex will exclude urls containing ?_pos
1
.*_pos.*
Exclude a Paramater
1
2
.*\?filter=.*
Exclude Directory from Crawl
1
https://example.com/exclude/.*
Use cases
you can exclude duplicate urls. such as for Ecommerce sites where urls containing query paramaters for size and color etc
Find all links to pdf’s
- Run crawl
- View all html links
- Select all html links
- Select
inlinksfrom the bottom row - Filter by pdf
Find all images missing alt text
- Run crawl
- Select images tab from the top panel
- Filter by missing alt text
Search Entire Site for some String of Text
It’s such a useful ability to be able to search an entire website and return all the urls that contain an occurrence of a specific word or string or phrase.
Use Screaming Frog to find all Occurences of this HTML or String
- Go to configuration > custom > search
- Enter search string (you can search for more then 1 string)
- In the search crawl results find the custom search column relating to your search
Case sensitivity
By default the search is not case sensitive so if you search for the word lawyers it will also pick up the word Lawyers & LAWYERS
Use cases
There are many use cases but the most practical one i use it for is to locate a string of text on a any size website, large or small.
For instance, use frog to find “Lorem ipsum” dummy text which needs updating.
Crawl a Password Protected Site
If the site has a browser password protection that’s no problem for screaming frog. Screaming frog will ask you to enter the username and password of the website before crawling to site.
Cannot see the text
If you cannot see the text on your website but Screaming Frog can. The text is hidden. Could be in a slideshow, accordion or tabs.
You can view html source of a website in your browser and search for the string in the html code. You will see it now.
Other Options
Some command line options such as Curl curl allow you to search 1 webpage for a string of text but not the entire site. To search the entire site for string of text you will need the Screaming Frog.
How to crawl a noindex nofollow site with Screaming Frog
Most of the time WordPress puts noindex/nofollow sitewide on each page. Due to the settings in the Reading Settings.
 You could uncheck this box, then quickly crawl the site with Screaming Frog. But this is not best practice.
Its dangerous as you may forget to reapply the discourage Search engines box. This could utimately lead to your staging site being served up in the serps to your audience.
You could uncheck this box, then quickly crawl the site with Screaming Frog. But this is not best practice.
Its dangerous as you may forget to reapply the discourage Search engines box. This could utimately lead to your staging site being served up in the serps to your audience.
It’s best to tweak the Screaming Frog Crawl settings as outlined below.
How to bypass the nofollow
- Go to ‘Config > Spider’
- Scroll down to “Crawl behaviour”
- enable ‘Follow Internal Nofollow’

How to bypass the noindex
- Go to ‘Config > Spider > Advanced’.
- Uncheck Ignore Non-Indexable URLs for Issues

Now you can Crawl a site set to noIndex NoFollow
How to bypass robots.txt
Bypass the nofollow When the nofollow has been added to the Robots file.
- Go to ‘Config > Robots.txt > Settings’
- Choose ‘Ignore robots.txt’.
