Screaming Frog Cheatsheet
Configure Screaming Frog settings to crawl sites and fix 404s.
** Prerequisites **
Screaming Frog installed on your Computer (there is a free version) Screaming Frog is a desktop application you can download to your computer
Find lorem ipsum text
Screaming frog has a built in feature for this.
- Crawl site
- Go to the content tab
- Filter by
lorum ipsum placeholder
Find # links, jump links, named anchors,
Follow these steps:
- Enable Crawl Fragment Identifiers:
- Open Screaming Frog SEO Spider.
- Go to
Configuration > Spider > advanced. Check the box for Crawl Fragment Identifiers. This setting allows Screaming Frog to crawl and analyze the # part of URLs.
Now links like https://example.com.au/contact-us/#content will appear in the results.
Customising a Screaming Frog Crawl
Exclude urls from crawl
When crawling a big site with screaming frog sometimes the results are too overwhelming due to the sheer volume. As the devil is in the details and the proof is in the pudding it can be really helpful to exclude some of the unwanted urls.
This tutorial will show you how you can exclude urls from the screaming frog crawl so you can return only the most relevant urls related to your goal.
Go to configuration > exclude
Exclude a word from the crawl
This regex will exclude urls containing ?_pos
1
.*_pos.*
Exclude a parameter
1
.*\?filter=.*
Exclude directory from crawl
1
https://example.com/exclude/.*
Search for strings
It’s such a useful ability to be able to search an entire website and return all the urls that contain an occurrence of a specific word or string or phrase.
Find all occurrences of some HTML or String
- Go to
configuration > custom > search - Enter search string (you can search for more then 1 string)
- In the search crawl results find the custom search column relating to your search
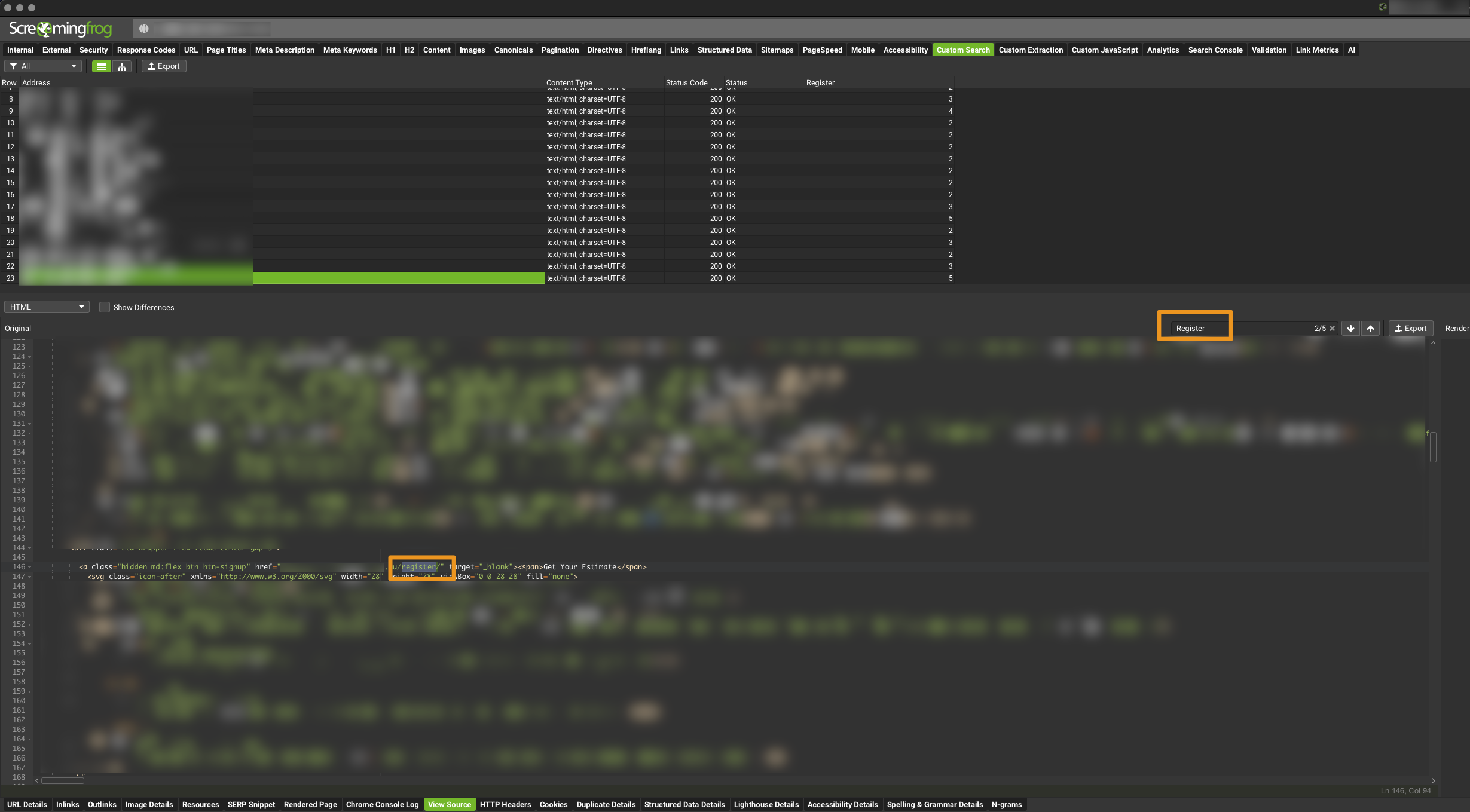
Search source for the word
- in your custom search tab
- hit view source in the bottom (ensure store html is set in
Configuration / Extraction / store html - Your can use the built in search to locate the occurrences
Case sensitivity
By default the search is not case sensitive so if you search for the word lawyers it will also pick up the word Lawyers & LAWYERS
find video files
Ensure media is ticked 
Now you can filter by media
Search more video file types
by default this will only search mp4. go to configuration > include to add more file types
1
2
3
.webm
.mov
.avi
Crawl a Password Protected Site
If the site has a browser password protection that’s no problem for screaming frog. Screaming frog will ask you to enter the username and password of the website before crawling to site.
If you cannot see the text on your website but Screaming Frog can?
If you cannot see the text on your website but Screaming Frog can. The text is hidden. The text could be hidden in a slideshow, accordion or tabs. View html source of a website in your browser and search for the string in the html code. You will see it now.
Crawl the logged in area of a site
Go to configuration > authentication > form login. Screaming Frog will open a popup window for the login area of the site. Just log in and your done.
Fix 404’s.
Overall, fixing 404 errors is essential for maintaining a healthy website that provides a positive user experience, preserves SEO performance, and builds trust with visitors and search engines alike.
How to find the 404 errors
This is arguably the hardest part about 404 errors and its the heart of this tutorial.
- Run the crawl on your site url
- Filter by status code until 404 descend from the top
- Select any of the 404’s from the returned results.
- Look at the footer menu of Screaming Frog for
inlinks - Right click the url from the
fromcolumn - Hit open from in browser
- Search for the anchor text of the broken link by doing a “command f” in your browser window
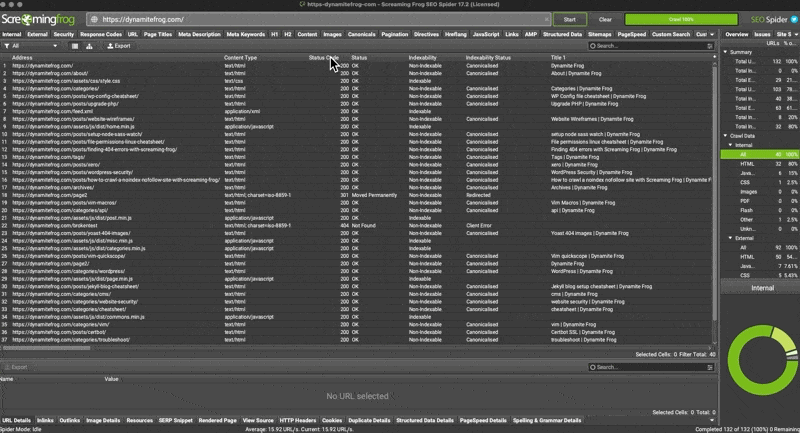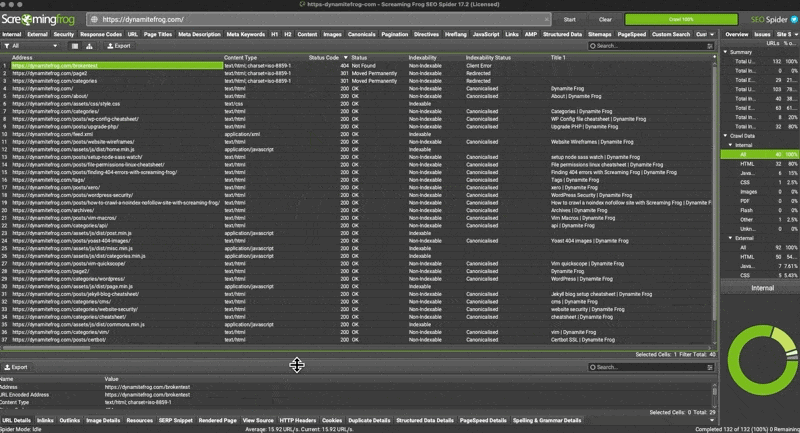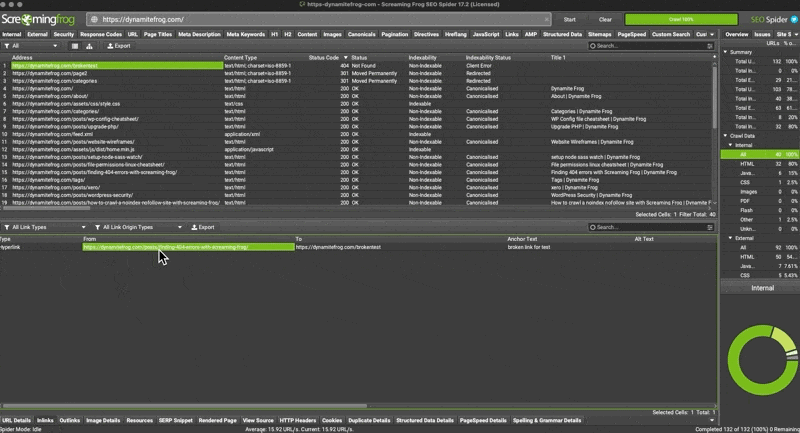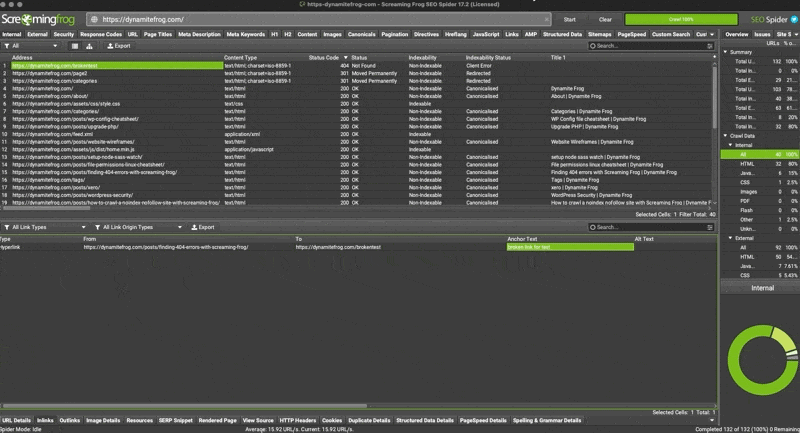 find 404’s with Screaming Frog Crawl
find 404’s with Screaming Frog Crawl
If you can’t replicate the broken link in Screaming Frog
- If you cant replicate the link it could be that you are logged in (And Screaming frog is not) and therefore cant replicate the error. Test the broken link in a non-logged in state.
- Try search the html source code if the search for the string on the website frontend returns 0 correct results
Crawl No-index site.
What is the no index / no follow site settings
The “noindex” and “nofollow” site settings are directives that can be implemented in the HTML code of a webpage to instruct search engines on how to handle the page and its links:
Noindex: This directive tells search engines not to index the content of the page. In other words, the page won’t appear in search engine results pages (SERPs). This is commonly used for pages that are not intended to be publicly visible or for duplicate content that shouldn’t be indexed.Nofollow: This directive tells search engines not to follow the links on the page. It means that search engine crawlers won’t pass authority or PageRank to the linked pages, and those pages won’t benefit from being linked to from the “nofollow” page.
Combining both directives, noindex, nofollow is often used for pages that the website owner doesn’t want to appear in search results and doesn’t want to pass authority to other pages through links on that page.
These directives are typically implemented using meta tags in the HTML code of a webpage. For example:
1
<meta name="robots" content="noindex, nofollow" />
Or they can be set through the robots.txt file or with HTTP response headers. They are useful for controlling how search engines interact with specific pages or sections of a website.
How to bypass the nofollow when crawling a site with Screaming Frog
- Go to ‘Config > Spider’
- Scroll down to “Crawl behaviour”
- Enable
Follow Internal Nofollow

How to bypass the noindex
- Go to
Config > Spider > Advanced. - Uncheck Ignore Non-Indexable URLs for Issues

Now you can Crawl a site set to noIndex NoFollow
How to bypass robots.txt
Bypass the nofollow When the nofollow has been added to the Robots file.
- Go to ‘Config > Robots.txt > Settings’
- Choose ‘Ignore robots.txt’.

Disable crawling javascript enabled pages
To disable JavaScript crawling in Screaming Frog, follow these steps:
Open Screaming Frog SEO Spider: Launch the application.
Go to Configuration:
From the top menu, click on Configuration.
Select Spider Settings:
In the drop-down menu, go to Spider….
Disable JavaScript:
In the Spider Configuration window, uncheck the option ‘Render: JavaScript’ under the Rendering tab. This ensures that Screaming Frog won’t crawl the JavaScript-rendered versions of your pages, and it will focus only on the raw HTML.
Click OK: Save your settings by clicking OK.
By disabling JavaScript crawling, Screaming Frog will now crawl your site in its default HTML-only mode.
Find all images missing alt text
- Run crawl
- Select images tab from the top panel
- Filter by missing alt text
Find duplicate Meta descriptions
- Run crawl
- Hit meta description tab
- On the right under the “overview tab” hit duplicate
- And then click on the duplicate graph - this will filter your crawl results on the left.
- now the filter is in place you can export the csv of this data
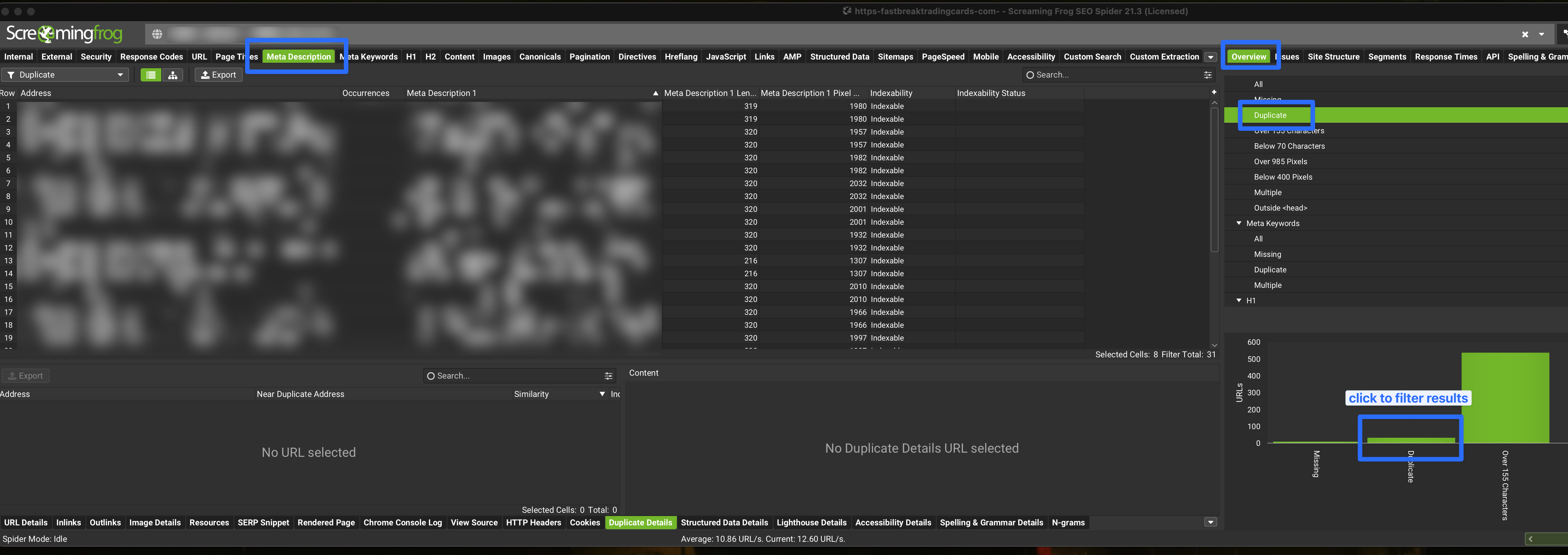
speed up the Crawl and resolve memory issues.
Set storage to save to database. This will make the crawl insanely fast. screamingfrog > Settings > Storage Mode
allocate more memory:
screamingfrog > Settings > Memory Usage
Drop the speed and limit urls if site is refusing to be crawlled. This will be much slower but more successful.
** > [!WARNING] this can also block your ip from accessing the site.